Introduction
Last Saturday evening (the 14th of September), I attended the play-offs of the
2013 Entelect Artificial Intelligence Programming Challenge.
Last year the theme was based on the Tron light-cycles game, but on a sphere instead of a grid. This year the theme was inspired by the 1980's tank warfare game,
Battle City.
Here's a whirlwind summary of
the game rules...
There are 8 fixed boards ranging in size from about 61x61 to 81x81. Each player has 2 tanks. A play wins by either shooting or driving over the enemy base. Bullets move at twice the speed of tanks, and tanks can shoot each other and shoot through walls. Tanks occupy a 5x5 area. Bases and bullets occupy a single cell. When a wall is shot, the two walls on either side are also destroyed (thus allowing a tank to shoot a path through the walls). If tanks try to move into a wall or another tank, the tank will turn but not move. A tank can only have one bullet in play at a time. So the tank is effectively disarmed until its bullet hits a wall, another tank, a base or the edge of the board. Both players move simultaneously and there are 3 seconds between turns. The players communicate with the game engine via SOAP web service calls.

Last year there were over 100 competitors, but this year the challenge was definitely a few notches up in complexity. In the end there were only 22 contestants. So I was expecting the play-offs to be much quieter than last year. But fortunately it wasn't like that at all.
As with last year's competition the camaraderie was superb. There was a lot of lively chatter. And it was great to put faces to some of the people I had been interacting with on
the unofficial google groups forum for the competition.
My path to the play-offs
My first bot
Although I worked hard on my bot, I had also been working crazy hours at work and I was still quite tired. But I was given a couple of days off work to compensate for the long hours I had been working. So I don't think the hours at work affected my productivity too much (I ended up writing over 15 000 lines of code in the 7 weeks of the competition). But I think I made more careless mistakes than I usually would.
Between my own bugs and quite a few bugs and race conditions in the official test harness, I lost most of the final week of the competition to bug fixing. I found myself with a number of really nice algorithms, but with no bot to make use of them!
The result is that I very nearly didn't submit a bot at all. My initial entry used a very basic heuristic of having one tank take the shortest path to attack the enemy base and the other tank attack the closest enemy tank. It had very basic bullet avoidance code which I added at the death (so to speak), and which hadn't been adequately tested.
At that stage I had given up on doing well. My main reason for entering was to attend the play-offs, meet up with some of the other contestants and enjoy the superb spirit of the event. I had very low expectations for my bot and I named it "Vrot Bot".
Vrot Bot
"Vrot" is the Afrikaans word for rotten. Like many Afrikaans words it has become a standard part of English slang in South Africa.
It is pronounced like the English word "fraught", but with a short vowel sound and a rolled "r". But if you're an English-speaking South African, you will mis-pronounce it slightly so that "vrot" rhymes with "bot". So it will sound like "frot bot".
The entry date gets extended
Due to the small number of competitors and some technical issues with the test harness, the competition ended up being extended twice.
This gave me an extra week to put a much more sophisticated bot together. However it was only in the last 24 hours of the competition that my new bot ended up beating the original vrot bot convincingly. And a lot of the new code had not gone through nearly enough testing, so it was bound to be buggy.
On that basis I decided to keep the name Vrot Bot.
Testing, testing, testing...
Last year I came fourth in the competition. My secret sauce was building a WPF user interface that allowed me to play against my bot, save and load games, rewind games to arbitrary points in their history, visualize a variety of parameters at each cell of the board and drill down into the search tree of moves (I used
the NegaMax algorithm to choose moves). I ended up with a very robust, well-tested bot.
Although I had planned to do something similar this year, the competition had a much shorter duration than last year and I never quite got there. At one point I had a choice between writing my own test harness and using the official test harness provided by the organisers.
I chose to use the official test harness, because I was concerned about the risk of integrating a C# WCF web service client with the SOAP web service exposed by the Java test harness. So I wanted to test that integration as thoroughly as possible, and my own test harness wouldn't have provided that capability.
I ended up using a variety of simpler methods for testing my bot's logic. However this made the test cycle much slower, and I paid the price in having a much buggier bot. There were many parts of my code which were very poorly tested because I simply didn't have a quick and easy way of forcing the game into the scenario I wanted to test.
If there was only one thing I could change about my approach to this year's competition, it would be to write my own test harness (as well as using the official test harness for testing integrations). That would have given me the ability to load a previously played game at any point in its history, instead of having to wait minutes for the harness to reach the turn where I knew the bug to be.
Performance tuning...
Last year my bot's main weakness was its slow performance. The first and third-placed players both used C++ for their bots, so having good performance gave a distinct competitive advantage. So this year I put a lot more effort into tweaking the performance of my bot.
There's a very true saying that premature optimization is the root of all evil. I was well aware of this. However I also felt that to get really good performance the data structures would need to be designed with performance in mind. And that's something that's not easy to change later if you get it wrong.
With hindsight I shouldn't have spent as much time worrying about performance. The search space for this year's challenge was massive. That meant that a brute force approach was far less valuable than last year. My time would have been better spent improving my testing capability.
The play-offs
The 22 contestants were grouped into 4 round robin pools with 5 to 6 players per pool.
Many of the matches were decided on silly mistakes, so I think many of the other contestants had also been struggling with the same issues: the shorter competition timeframe, a much more complex problem space and difficulties with adequately testing their bots.
My bot performed much better than I was expecting. I topped my pool quite easily, winning 4 of my 5 pool matches.
Strangely enough, my bot seemed to be a lot more decisive than I was expecting. But I didn't think too much of it at the time.
My one loss was on a smaller, fairly open board. Bullet-dodging was something I had tested quite thoroughly. Yet my tanks ran straight into the enemy tanks' bullets instead of dodging them. That was also quite surprising.
My bot's algorithm is based on running through a number of scenarios and, for each applicable scenario, calculating a value for each of the 6 possible tank actions for each tank. At the time I suspected that a number of scenarios had combined to create a cumulative value for moving forward that was greater than the value of either dodging or shooting approaching bullets.
It was only a few days later that I discovered the real reason for the lack of bullet-dodging behaviour... but I'll get to that later.
The elimination round
I was expecting the top 2 players in each pool to go through to the finals at the
rAge computer gaming expo on 5 October. However there was a twist in proceedings...
The players were seeded based on how many games they had won in the pool stage. The top 16 seeds went into an elimination round. The elimination round worked as follows: seed 1 played seed 16, seed 2 played seed 15, and so on. The winners of those 8 matches would go through to the finals at rAge.
Although I was one of the top 5 seeds, I had a sinking feeling at this point as a single loss could knock one out the tournament. Imagine my feeling when I saw the board for my knock-out game... It was the same board as my one loss in the pool rounds! And sadly the result was the same... my tanks raced towards the enemy tanks, ate a bullet each and I was knocked out the competition!
I was disappointed and a little irritated that everything had hinged on a single game. At least last year the format was a
double elimination, so a single bad game couldn't knock a good bot out of the competition.
On the other hand, my expectations had been low to begin with. So the end result wasn't different from what I had been expecting. And I had the added satisfaction of knowing that my bot had generally been much stronger than expected. So all I could do was be philosophical about the loss...
The debacle of the official test harness
Bots that froze
Something surprising and quite sad happened to some contestants. On start-up their bots froze and did nothing for the rest of the game.
Last year's winner, Jaco Cronje, had this problem on a number of boards. But he won easily when his bot played. Fortunately he won enough games to be one of the lower seeds of the top 16, and during the knockout round he got the board that his bot did not freeze on. He won that game easily and made it through to the finals.
Another competitor, Bernhard Häussermann, had a similar issue which prevented his tank from moving in any of his games. This is very sad when you consider how much effort people put into their entries for the competition.
But was it really his own error that led to the frozen tanks?
The mysterious case of the frozen tanks
In the week after the play-offs Jaco and Bernhard went on a mission to identify the reason for their tanks freezing.
During the final weekend before submission, Jaco had set his bot running through the night to check for weird issues. It had run fine. The competition organisers had said they would use the same test harness to run the competition as they had provided for the players to test against. So how was it possible for Jaco to get a different result during the play-offs?
The details of their digging are on
this page of the google group for the competition. Here's the short version...
A number of players had noticed that the id's of the 4 tanks were always 0, 1, 2 and 3. One player would get tanks 0 and 3. The other player would get tank id's 1 and 2. Since tank movement was resolved in the order of tank id's, this ordering made it a little fairer to choose who got precedence when two tanks tried to move into the same space on the same turn.
But in the play-offs the test harness started assigning very large tank id's. This caused out of range exceptions for some of the bots when they tried to save the tank information into a much smaller array.
Perhaps the test harness was modified to run multiple games without requiring a restart, instead of the correct approach of building a "tournament runner application" which would re-start the unmodified test harness between games.
So why didn't my tanks dodge bullets?
On Wednesday I had a hunch about why my bullets didn't dodge bullets. And why they seemed to behave differently to what I'd been expecting.
So on Wednesday evening, after getting home from a
Data Science meetup group, I put my hunch to the test.
I simulated a tank id outside the range of 0 to 3. As expected, this caused my bot to also throw an out-of-range exception in the part of my code which configures tank movement sequences.
The reason my bot didn't freeze is that I had put in a fail-safe mechanism to catch any errors made by my bot.
If an error occurred, I would see if my bot had made a move yet. If it hadn't, I would run a very simple algorithm so that it would at least make a move rather than just freezing. My closest tank would attack the enemy base, and my other tank would attack the closest enemy tank. There was no bullet dodging logic, as I didn't want to risk running any extra code that could have been the cause of the original error.
So this explains why my bot had failed to dodge bullets. And also why it had acted so single-mindedly.
I had worked so hard on my scenario-driven bot in the final (extended) week of the competition. And it probably didn't even get used due to this bug. How sad. Since I still won my pool with this very basic bot, imagine what I could have done with my much more sophisticated bot!
[Bernhard was in the same pool as me. So without the tank ID bug I might not have won the pool. But at least my best bot would have been on display.]
To be or not to be bitter
So at this point I have two choices...
Jaco and Bernhard have decompiled the jar file for the official test harness, and there should be no way that the test harness can assign a tank id out of the range 0 to 3. So the organizers must have changed the test harness after the final submission date, in which case it nullifies its purpose as a test harness. I could choose to be bitter about this.
My second choice is to suck it up and learn from the mistakes that I made. And I can only do that if I don't take the easy way out by blaming someone else for what went wrong (tempting though that is).
I used a variety of defensive coding practices, including my fail-safe algorithm. But I failed to code defensively against the possibility of the tank id's being outside the range of 0 to 3. I have a vague memory of feeling very uncomfortable at making this assumption. But I made the poor judgement call of ignoring my intuition and going with a cheap solution rather than the right solution (or even just a cheap solution with more defensive coding). That mistake is my mistake, and it's something I can learn from.
Keeping the goal in mind
The big picture with entering competitions like this, is that you are not doing it for the prize money or the fame (though those are useful motivators to help give you a focus for your efforts). Doing so would be a form of moonlighting and is arguably unethical.
To some extent you are doing it for the fun and the camaraderie - the opportunity to interact with smart developers who enjoy challenging themselves with very tricky problems. But I get similar enjoyment from playing
German-style board games with my colleagues and friends - and with far less investment of time.
However the most important reason is for the learning experience. You are exposing yourself to a challenging situation which will stretch you to your limits, and in which you are bound to make some mistakes (as well as learn new coding techniques). The mistakes you make and the lessons you learn are part of your growth as a programmer.
With this perspective I would rather learn from my mistakes than look for someone to blame.
The alternative is to become bitter at the injustice of the situation. But life is full of injustice, and in many cases (such as this one) it is not caused by malevolence, but simply by human fallibility. As software developers we know all too well how seemingly innocuous changes can have unexpectedly large side-effects.
I'm not advocating that we should lower the standards we set for ourselves and others. But I think we should balance that against having the maturity to forgive ourselves and others when we make unfortunate mistakes despite our best intentions.
The most valuable lesson I learnt
The most valuable lesson learnt was not about coding more defensively. Or about making testability a primary consideration. Or to avoid premature optimization. Or even to listen to my gut feeling when I'm feeling uncomfortable about code that I'm writing (valuable though that is).
Those are all things I already knew. As the saying goes, experience is that thing that allows you to recognise a mistake when you make it again!
The most valuable lesson was a new insight:
beware of the second system effect!
Last year I placed fourth in the challenge with a fairly standard NegaMax search tree approach. I was conservative in my approach, did the basics well, and got a great result! But I had some innovative ideas which I never got as far as implementing...
This year I wanted to do better than last year. And I wanted to push the envelope more. And as a result I fell foul of the second system effect, and did worse than last year.
And this is not the only recent instance of this happening...
In 2011 I did really well in the
UDT Super 15 Rugby Fantasy League with a simple statistical model (built in Excel) and a linear programming model for selecting my Fantasy League team each round. And I placed in the 99.4th percentile (183rd out of around 30 000 entrants)!
In 2012 I wanted to do even better, so I used
the R programming language to build a much more complex statistical model. I put a lot more effort into it. Yet I only placed in the 90th percentile. The second systems effect again!
In both cases I learnt far more from my second system than from the more conservative (but more successful) first system. So it's not all bad, since learning and self-development is the primary goal. But in future I'd like to find a better balance between getting a good result and "expressing my creativity".
Wrap-up
As one of the eight finalists in the 2012 competition, I ended up being interviewed after the play-offs last year. That interview can be found
on youtube.
Although I didn't make it to the final eight this year, I still found myself being roped into an interview. I'll update this page with the link once that interview has been uploaded to youtube.
For anyone who's interested, I've also uploaded the source code for my bot entry
on GitHub.
There's more detail on the approach that I and the other contestants took at
this page on the google groups forum.
What's next?
At some point I'd like to post a blog entry on my shortest path algorithm, as I came up with a neat trick to side-step the various complexities of doing a Dijkstra algorithm with binary heaps, pairing heaps, r-divisions on planar graphs, and so forth.
But first I'd like to wrap up
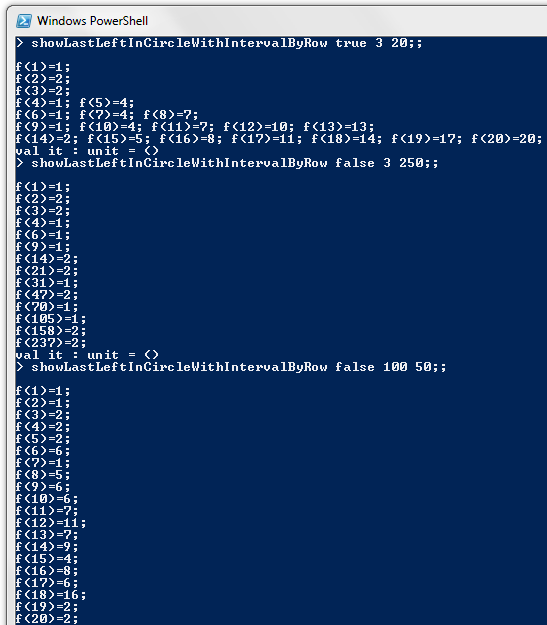
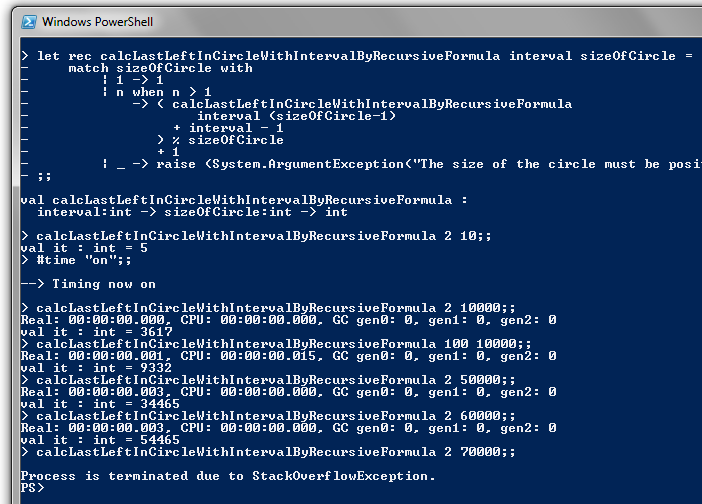
my series of posts on an interesting problem in recreational Mathematics known as the Josephus problem.